길고 긴 개선 과정을 거쳐 최종적으로 마무리한 Kafka Parallel-Consumer의 선정과 결론에 대해 정리하고자 한다.
개선 과정이 궁금하신 분께서는 아래 내용을 참고해주시면 감사하겠습니다.
2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(1)
2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2)
2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완))
배경
기능 요구사항을 다시 한번 살펴보자.
- 사용자 1명당 N개의 알림을 받을 수 있다.
- 추후 알림 별 시간 설정 기능이 추가될 수 있으나, 현재 모든 알림이 동일한 시간에 제공된다.
- 사용자는 알림 수신 여부를 설정할 수 있다.
이에 대한 기능 구현을 완료했다.
알림 시스템에 대한 현재까지의 구현 사항은 다음과 같다.
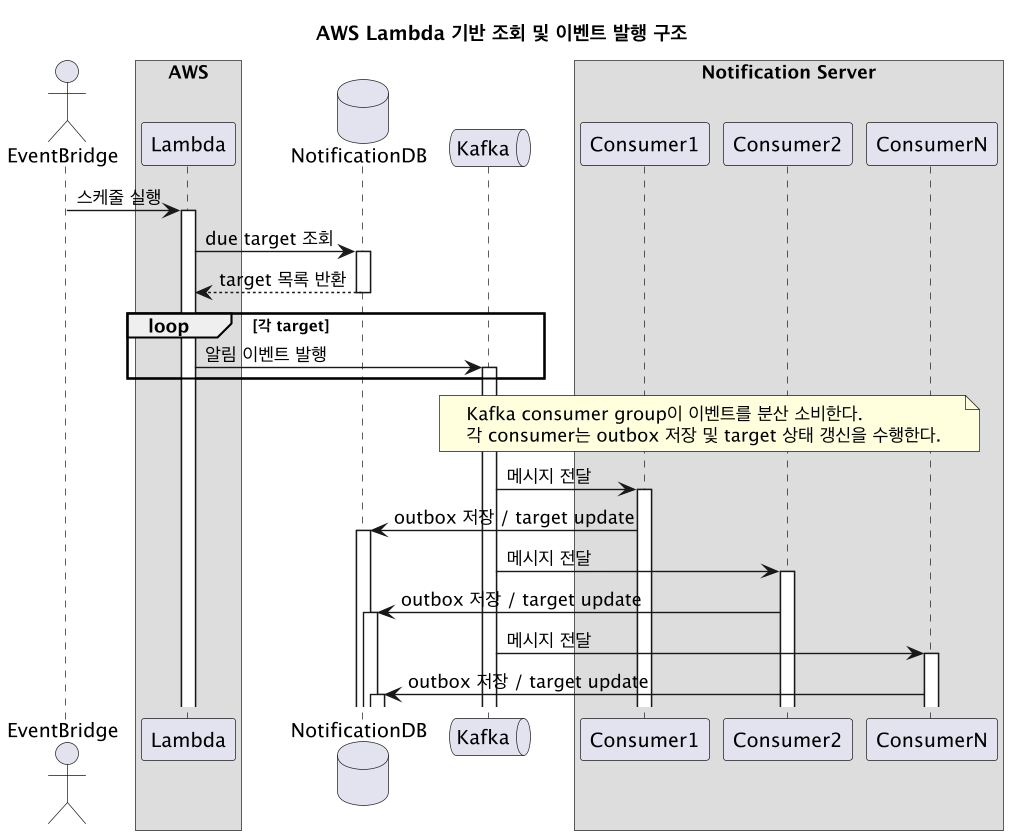
- AWS Lambda를 통해 스케줄러를 서비스와 분리하여 이벤트를 발행한다.
- Consumer 서버들이 이를 처리한다.
- Batch 처리를 통해 처리량을 올린다.
문제 상황

[GREENROOM KAFKA BATCH BENCHMARK]
eligible=100000,
outboxCreated=100000,
eventPublishSec=0.649,
totalSec=38.944,
msgsPerSecond=2567.79배치 작업을 통해 초당 약 2600개의 알림을 전송하고, 이는 기능 요구사항인 “1분 내에 10만개의 알림을 전송해야한다.” 를 달성했다.
하지만 이러한 궁금증이 남았다. 10만 건의 알림이 아니라, 더 많은 알림을 전송해야 한다면 어떻게 해야 할까?
아래와 같은 결론을 내렸다.
- Kafka 토픽의 파티션 수를 늘린다.
- 처리할 서버 수를 늘린다.
- 서버를 늘릴 수 없다면, 하나의 서버에 더 많은 스레드로 여러 파티션을 처리한다.
결과적으로 파티션의 개수에 종속되는 문제이다.
협업 차원에서 카프카 파티션의 개수를 늘리기 위해 인프라팀을 설득해야했고, 이 과정 속에서 발견된 여러 문제점을 찾을 수 있었다.
1. 메시지 순서 보장 문제가 달라진다.
2. 파티션 수와 Consumer 수를 늘린다고 성능이 선형 증가하는 것은 아니다.
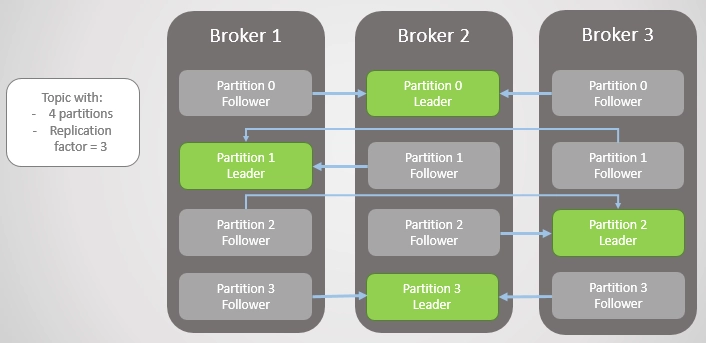
3. 파티션 수가 많아질수록 운영 비용도 증가한다.
4. 리밸런싱 비용이 커질 수 있다.
5. 파티션 증설은 쉽지만, 되돌리는 것은 불가능하다.
즉 단순히 “더 빠르게 처리하고 싶다”는 이유만으로 파티션을 계속 늘리는 것은 적절한 해결책이 아니었다.
해결책 선정
이 지점에서 찾은 것이 Kafka Parallel Consumer 이다.
https://github.com/confluentinc/parallel-consumer
GitHub - confluentinc/parallel-consumer: Parallel Apache Kafka client wrapper with per message ACK, client side queueing, a simp
Parallel Apache Kafka client wrapper with per message ACK, client side queueing, a simpler consumer/producer API with key concurrency and extendable non-blocking IO processing. - confluentinc/paral...
github.com
Confluent의 Parallel Consumer는 하나의 Kafka Consumer 인스턴스 안에서 여러 레코드를 동시에 처리할 수 있게 해 주는 래퍼 라이브러리다. 이 라이브러리를 통해 토픽 파티션 수를 늘리지 않고도 consumer parallelism을 높일 수 있다.
두 시스템을 비교하자면 다음과 같다.
| 항목 | 기존 Kafka Consumer | Kafka Parallel Consumer |
|---|---|---|
| 병렬성 기준 | 기본적으로 파티션 단위 | 단일 consumer 내부에서도 동시 처리 가능 |
| 병렬성 확장 방법 | 컨슈머 수 증가 또는 파티션 수 증가 | maxConcurrency 조절로 확장 가능 |
| 파티션 의존도 | 높음 | 상대적으로 낮음 |
| 동일 파티션 내부 처리 | 보통 순차 처리 | 여러 레코드 동시 처리 가능 |
| 순서 보장 옵션 | 기본적으로 파티션 순서 중심 | UNORDERED / PARTITION / KEY 선택 가능 |
| offset commit 관리 | 병렬 처리 시 직접 관리 복잡 | 라이브러리가 commit 처리 지원 |
| 적합한 상황 | 단순 구조, 파티션 기반 확장이 충분할 때 | 파티션 수를 늘리지 않고 처리량을 높이고 싶을 때 |
| 장점 | 단순하고 표준적 | 높은 동시성, ordering 전략 선택 가능 |
| 주의점 | 파티션 수가 병렬성 상한 | UNORDERED는 순서 민감한 서비스에 부적합 |
이 라이브러리를 해결책으로 검토한 이유는 두 가지였다.
1. 현재 구조에서는 파티션 수를 무작정 늘리기보다 기존 토픽 구조를 유지하면서 처리량을 높이는 것이 더 적절했다.
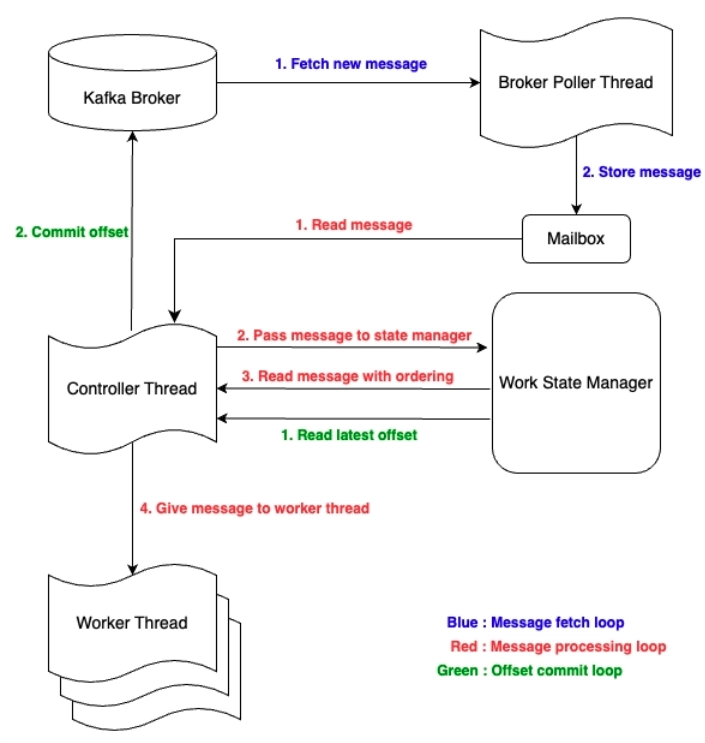
2. 일반 Kafka Consumer에서 애플리케이션 레벨로 스레드 풀을 붙여 병렬 처리하려면 offset commit과 ordering 보장, retry 처리를 직접 관리해야 해서 구현 복잡도가 높다. Parallel Consumer는 이 부분을 감싸 주고, 개발자는 처리 함수에 더 집중할 수 있도록 설계되어 있다.
무엇보다 기획 요구사항은 “순차 처리” 보다는 “시간 내 도착”이 더욱 중요한 문제였다.
Kafka가 기본적으로 보장하는 건:
- 같은 파티션에 들어간 레코드들은 오프셋 순서대로 읽힌다
- 컨슈머가 그 순서대로 처리할지는 애플리케이션이 어떻게 구현하느냐에 달려있다(특히 병렬 처리하면 깨지기 쉬움)
즉, Kafka는 “읽히는 순서”는 주지만, 병렬 처리에서 “처리 완료 순서”까지 자동으로 맞춰주진 않는다.
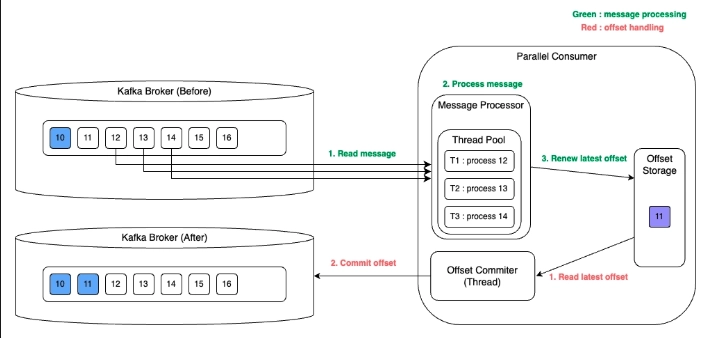
예를 들어, 11을 커밋하는 순간 10도 처리된 것으로 간주될 수 있다.
Parallel-Consumer은 이런 요구를 겨냥해 순서 보장 범위를 파티션 전체 → 키 단위 → 무순서로 단계적으로 제시한다.
그 중에서도 순서가 필요없고, 처리량이 더욱 중요한 서비스 특성상 무순서 방식을 고려했다.

순서를 전혀 신경쓰지 않고 처리 가능한 쓰레드가 맡아 처리하는 방식으로 작업이 진행된다.
도입
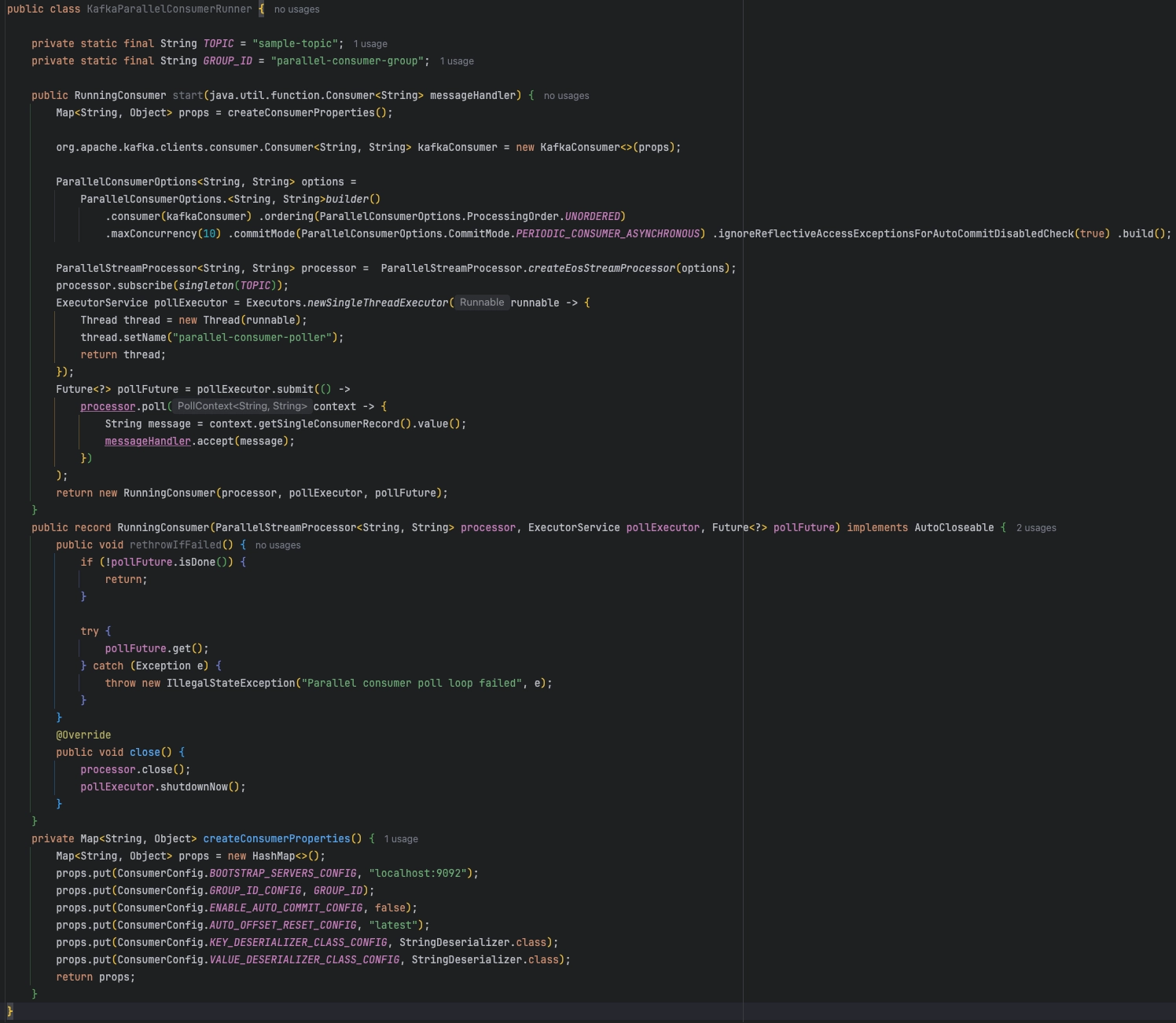
.ordering(ParallelConsumerOptions.ProcessingOrder.UNORDERED)
메시지 처리 순서 정책을 정하는 옵션이다.
UNORDERED는 순서를 보장하지 않는 대신 가장 높은 동시성을 확보할 수 있다.
기능 요구사항을 완벽히 충족시키는 정책이다.
.maxConCurrency(10)
동시 처리 작업 수의 상한을 정하는 옵션이다.
파티션 개수와 별개로 최대 10개의 레코드가 병렬로 처리될 수 있다.
무조건 높다고 좋은 것은 아니기에 여러가지 상황에 대한 테스트 진행 후 10개로 변경하였다.
.commitMode(ParallelConsumerOptions.CommitMode.PERIODIC_CONSUMER_ASYNCHRONOUS)
offset commit 방식을 정하는 옵션이다.
해당 설정은 offset을 주기적으로 비동기로 커밋하는 방식이다.
커밋 호출이 너무 자주 발생하는 상황을 방지하기 위해 설정했다.
다만 비동기 커밋 특성 상 일부 메시지에 대한 재처리가 발생할 수 있다.
이는 알림을 db에서 조회해가는 서비스 특성을 이용하여 재처리가 발생하더라도 사용자가 느낄 수 없도록 처리했다.
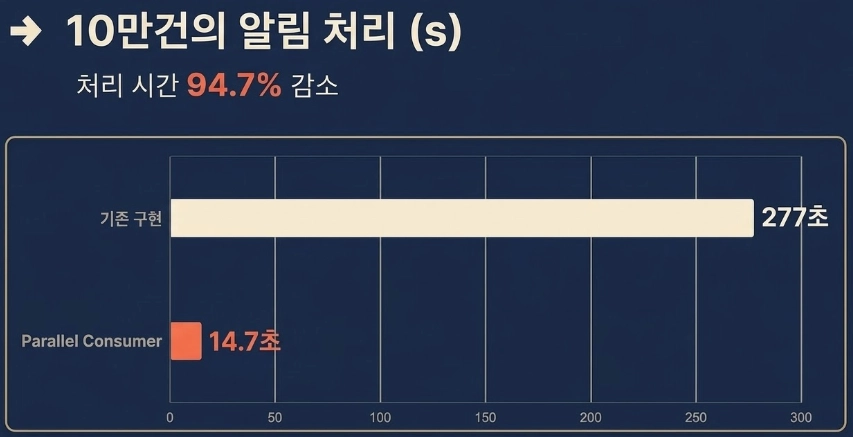
결과
‼️💡 최종 개선 결과 💡‼️
- 초당 처리량 362.12건 → 6,767.27건
- 약 18.7배 성능 향상

# 5 Thread
[GREENROOM KAFKA PARALLEL-CONSUMER BATCH BENCHMARK]
eligible=100000,
outboxCreated=100000,
eventPublishSec=1.277,
totalSec=19.868,
msgsPerSecond=5033.22
thread=pc-pool-4-thread-1, accepted=20938
thread=pc-pool-4-thread-2, accepted=20237
thread=pc-pool-4-thread-3, accepted=19929
thread=pc-pool-4-thread-4, accepted=20102
thread=pc-pool-4-thread-5, accepted=18794
# 10 Thread
[GREENROOM KAFKA PARALLEL-CONSUMER BATCH 10 BENCHMARK]
eligible=100000,
outboxCreated=100000,
eventPublishSec=1.297,
totalSec=14.777,
msgsPerSecond=6767.27
thread=pc-pool-4-thread-1, accepted=20938
thread=pc-pool-4-thread-2, accepted=20237
thread=pc-pool-4-thread-3, accepted=19929
thread=pc-pool-4-thread-4, accepted=20102
thread=pc-pool-4-thread-5, accepted=18794
thread=pc-pool-7-thread-1, accepted=10246
thread=pc-pool-7-thread-10, accepted=9936
thread=pc-pool-7-thread-2, accepted=10413
thread=pc-pool-7-thread-3, accepted=10276
thread=pc-pool-7-thread-4, accepted=10161
thread=pc-pool-7-thread-5, accepted=9780
thread=pc-pool-7-thread-6, accepted=9872
thread=pc-pool-7-thread-7, accepted=10015
thread=pc-pool-7-thread-8, accepted=8721
thread=pc-pool-7-thread-9, accepted=10580최종적으로 선정한 10개의 쓰레드 방식은 초당 6767개의 알림을 처리하고 있다.
이는 최초 구현인 362건 대비 18.7배 상승한 결과이다.
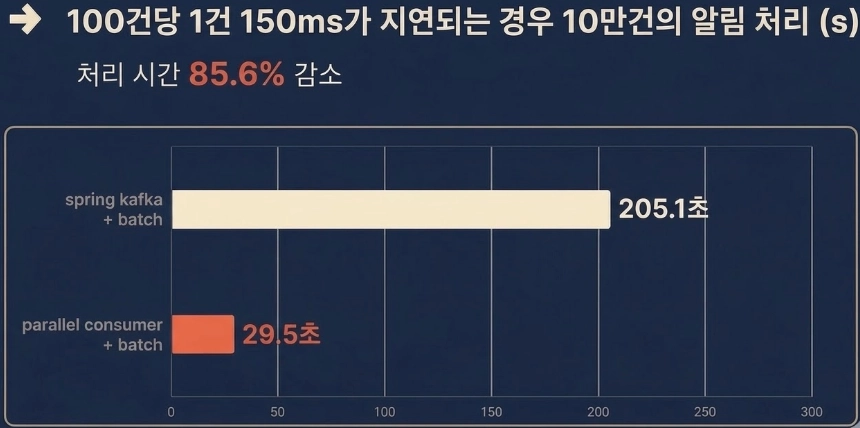
최종 시퀀스 다이어그램
출처 :
https://d2.naver.com/helloworld/7181840
https://www.youtube.com/watch?v=UhnERp2AYRo&t=1507s
https://github.com/confluentinc/parallel-consumer
'카프카' 카테고리의 다른 글
| [Kafka] 당신의 카프카는 zero copy입니까? (0) | 2026.03.29 |
|---|---|
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완)) (0) | 2026.03.21 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2) (0) | 2026.03.21 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(1) (0) | 2026.03.21 |
| [Kafka] Group, Topic, Record, Consumer, Partition 총 정리 (0) | 2026.01.05 |