Record
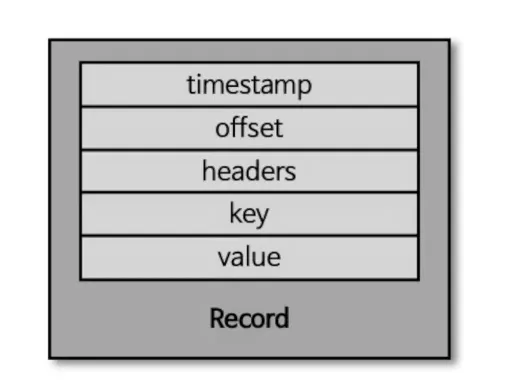
카프카 레코드의 구조는 위와 같다.
프로듀서가 생성한 레코드가 브로커로 전송되면 offset & timestamp가 지정되어 저장된다.
- timestamp
- 스트림 프로세싱에서의 활용을 위해 시간을 저장하는 용도로 사용된다.
- 따로 설정하지 않으면 PrdocuerRecord의 생성시간이 들어간다.
- 적재시간으로 변경할 수 있다.
- offset
- 프로듀서가 생성한 레코드에 존재하는 것은 아니다.
- 브로커에 적재될 때 오프셋이 지정된다.(0-based idx)
- 컨슈머는 오프셋을 기반으로 처리가 완료된 데이터와 처리하지 못한 데이터를 구분한다.
- 파티션별 고유한 오프셋을 가지므로, 컨슈머에서 중복 처리를 방지하기 위해서도 사용된다.
- headers
- key/value로 추가 가능하며 데이터를 넣어 사용 가능하다.
- key
- 처리하고자하는 메시지 값의 분류 용도로 사용된다. 이를 파티셔닝이라고 부른다.
- 파티셔너에 따라 토픽의 파티션 번호가 정해진다.
- 필수 값이 아니며, 지정하지 않을 시 NULL로 설정된다.
- 메시지 키가 Null인 레코드는 토픽의 파티션에 라운드로빈으로 전달된다.
- 2.4 버전 이후 매버 라운드로빈이 작동하는 것이 아닌 일정량이 채워지면 다른 파티션으로 이동하는 Sticky 방식을 사용한다.
- value
- 실제 처리가 될 데이터가 저장되는 공간
- 제네릭으로 사용자에 의해 지정되며, 컨슈머가 역직렬화 포맷을 알고 있어야 한다.
- 대부분 String으로 처리하고, 공간 낭비가 심한 경우 다른 형태로 사용한다.
하지만 이 레코드가 실제로 하나로 존재하는 것은 아니고, ProducerRecord와 ConsumerRecord로 나누어져 있다.
ProducerRecord
public class ProducerRecord<K, V> {
private final String topic;
private final Integer partition;
private final Headers headers;
private final K key;
private final V value;
private final Long timestamp;
}- topic
- record가 어느 topic으로 전송되어야하는지를 저장하는 값이며, 레코드 생성시 초기화한다.
public class ConsumerRecord<K, V> {
public static final long NO_TIMESTAMP = RecordBatch.NO_TIMESTAMP;
public static final int NULL_SIZE = -1;
/**
* @deprecated checksums are no longer exposed by this class, this constant will be removed in Apache Kafka 4.0
* (deprecated since 3.0).
*/
@Deprecated
public static final int NULL_CHECKSUM = -1;
private final String topic;
private final int partition;
private final long offset;
private final long timestamp;
private final TimestampType timestampType;
private final int serializedKeySize;
private final int serializedValueSize;
private final Headers headers;
private final K key;
private final V value;
private final Optional<Integer> leaderEpoch;- serializedKeySize & serializedValueSize
- producer record 단에서 직렬화한 key/value의 크기를 저장해놓은 값이다. 역직렬화시 사용된다.
- leader epoch
- leader epoch은 partition의 leader가 변경횟수를 기록하는 값으로 leader가 변경될 때마다 증가하는 값이다. 컨슈머는 이를 통해 리더가 언제 변경되었는지를 파악할 수 있으며, offset을 재조정하거나 데이터를 재처리해야 하는 시점을 판단할 수 있다.
Spring에서의 실제 사용
@Override
public CompletableFuture<SendResult<K, V>> send(String topic, K key, @Nullable V data) {
ProducerRecord<K, V> producerRecord = new ProducerRecord<>(topic, key, data);
return observeSend(producerRecord);
}KafkaTemplate의 send메서드를 보면 실제 ProducerRecord를 만들어서 메세지를 전송하는 것을 볼 수 있다.
public class KafkaMessageListenerContainer<K, V>{ // NOSONAR line count
...
private final BlockingQueue<ConsumerRecord<K, V>> acks = new LinkedBlockingQueue<>();
...
}일반적으로 @KafkaListener 어노테이션을 통해 처리하기 때문에 직접적으로 명시되어있지는 않지만 내부 과정을 살펴보면 다음과 같이 ConsumerRecord가 큐에 들어가있는 것을 확인할 수 있다.
Topic & Partition
Topic?
이벤트 스트림을 카프카에서는 토픽이라고 부른다. 카프카 세계에선 토픽이 구체화된 이벤트 스트림을 뜻한다. 이는 데이터 베이스의 테이블과 파일 시스템의 폴더와 유사하다.
토픽은 카프카에서 Producer/Consumer을 구분할 수 있게 한다. Producer은 카프카의 토픽에 메시지를 저장하고, Consumer은 저장된 메시지를 읽어온다. 즉, 하나의 토픽에 대해 여러 Producer/Comsumer가 존재할 수 있다.

다음과 같이 모든 토픽은 여러개의 Partition을 갖게 된다. 이는 사용자가 설정을 하거나, 기본값으로 지정되어 생성될 수 있다. 0-based idx로 시작한다.
public static class CreatableTopic implements Message, ImplicitLinkedHashMultiCollection.Element {
String name;
int numPartitions; // 파티션 수 지정
short replicationFactor;
CreatableReplicaAssignmentCollection assignments;
CreatableTopicConfigCollection configs;
private List<RawTaggedField> _unknownTaggedFields;
private int next;
private int prev;
}코드에서 알 수 있듯이 파티션은 토픽을 구성하는 요소이다.
Partition
토픽의 구성사항을 담당하는 것이 파티션이다. 즉, 토픽은 논리적인 개념에 가깝고, 파티션이 레코드를 실제 저장소에 저장하는 가장 작은 단위이다.
각각의 파티션은 Append-Only 방식으로 기록되는 하나의 로그 파일이다.
여기서 왜 Appen-Only인지 궁금할 수 있지만 이는 카프카가 offset을 이용해 정보를 관리할 뿐, 소멸시키지 않는다는 것과 가깝다.
파티션의 레코드는 각각이 Offset라 불리는 식별자 정보를 가지며, 이를 사용해 순서를 보장한다. 다만 모순적이게도 순서가 보장되지 않기도 한다. → 파티션 내부의 순서는 보장되더라도 파티션 간의 순서가 보장되지 않을 수 있다는 것이다.
하지만, 카프카가 흔히 순서가 보장된다 라고 하는 것은 하나의 컨슈머는 하나의 파티션에 붙어있기 때문이다.
파티션은 카프카가 병렬 처리, 순서 보장, 확장성의 장점을 제공하게 한다.
어떻게?
- 병렬 처리
- 각 파티션 별로 컨슈머가 존재하기 때문에 여러개의 파티션에 대해 컨슈머가 각각 처리하게 할 수 있다.
- 순서 보장
- 위에서 언급한 것과 같이 offset을 통해 처리 가능하다.
- 확장성
- 만약 하나의 파티션만 존재했다면 컨슈머가 추가되는 것이 매우 어려울 것이다. 하지만, 파티션이 존재한다면 파티션이 추가됨에 따라 컨슈머가 추가되면 손쉽게 확장 가능하다.
- 하나의 파티션만 존재한다면 토픽의 확장성은 브로커의 I/O 처리량에 의해 제약된다. 파티션들을 여러 브로커에 나눔으로써, 하나의 토픽은 수평적으로 확장될 수 있다.
그럼 파티션 분배는?
프로듀서가 데이터를 파티션에 할당할 때 키를 통해 파티션을 분배한다. 들어온 키를 해시함수를 통해 파티션을 설정하게되는 것이다. 하지만 이는 특정 파티션에 부하가 쏠리는 경우가 발생할 수 있다. 이를 대비하기 위해 키의 해시 분포가 균일하도록 키 선택 전략을 명확하게 정의해야한다.


Consumer & Group
Consumer
카프카의 최말단에 있는 컨슈머이다. 컨슈머는 컨슈머 API와 애플리케이션을 통칭하기도 한다.
카프카 컨슈머는 대표적인 3가지 특징을 갖는다
1. polling 구조
일반적으로 다른 메시징 큐는 메시지를 브로커가 푸시해준다. 이 방식의 가장 큰 단점은 메시지 큐가 컨슈머 측(서버 측)의 성능을 고려해야 한다는 것이다. 즉, 아키텍처를 설계하고 확장하는데 있어 양측 모두에 대한 고려가 직접적으로 필요하다는 것이다.
이와 반대로 카프카는 컨슈머가 브로커로부터 메세지를 요청하는 Polling 구조로 설계되어있다. 즉, 컨슈머가 자신이 처리 가능한만큼만 브로커에게 요청할 수 있다. 이를 통해 환경을 최적화할 수 있게 된다.
https://redis.io/docs/latest/develop/pubsub/
Redis Pub/sub
How to use pub/sub channels in Redis
redis.io
https://www.rabbitmq.com/docs/consumers
Consumers | RabbitMQ
<!--
www.rabbitmq.com
2.단일 토픽의 다중 컨슈밍
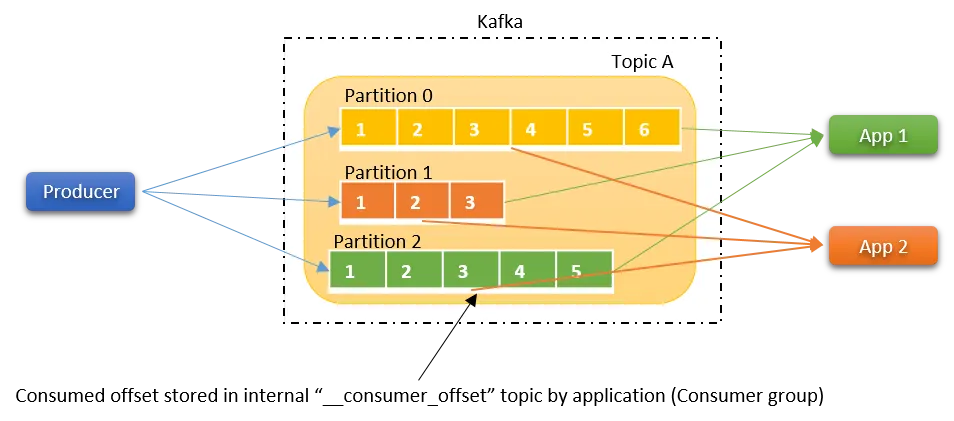
카프카 컨슈밍의 또 다른 중요한 특징 중 하나는 하나의 토픽을 여러 개의 서로 다른 컨슈머 애플리케이션이 동시에 구독할 수 있다는 점이다. 예를 들어 하나의 토픽(Topic A)을 컨슈머 App 1과 컨슈머 App 2가 동시에 구독할 수 있다. 이때 각 컨슈머 애플리케이션은 서로 독립적으로 동작하며, 동일한 토픽의 메시지를 각자의 목적에 맞게 소비한다.
이처럼 단일 토픽에 대해 멀티 컨슈밍이 가능한 이유는, 컨슈머가 메시지를 읽더라도 브로커에 저장된 메시지가 삭제되지 않기 때문이다. Kafka에서 메시지는 큐 방식이 아니라 로그(log) 형태로 저장되며, 컨슈머의 소비 여부와 관계없이 설정된 보존 정책(retention policy)에 따라 유지된다.
대신 Kafka는 각 컨슈머가 어느 토픽의 어떤 파티션에서, 어느 오프셋까지 메시지를 읽었는지를 별도로 관리한다. 이 정보는 컨슈머 오프셋(consumer offset) 이라 불리며, Kafka 내부에 존재하는 특수한 토픽인 __consumer_offsets에 저장된다. 컨슈머 오프셋은 컨슈머 그룹 단위로 관리되기 때문에, 서로 다른 컨슈머 애플리케이션 또는 서로 다른 컨슈머 그룹은 동일한 메시지에 대해서도 각자 독립적인 소비 위치를 가질 수 있다.
컨슈머 오프셋을 통해 얻을 수 있는 장점은 멀티 컨슈밍 지원에만 국한되지 않는다. 컨슈머 애플리케이션이 메시지를 구독하던 중 중단되었다가 다시 실행되는 경우에도, __consumer_offsets 토픽에 저장된 오프셋 정보를 기반으로 이전에 처리하던 지점부터 메시지 소비를 재개할 수 있다. 이로 인해 메시지 유실 없이 안정적인 재처리가 가능해진다.
결과적으로 Kafka는 컨슈머의 실행 상태와 관계없이 메시지 소비 위치를 브로커 측에서 안정적으로 관리할 수 있으며, 이를 통해 대규모 분산 환경에서도 신뢰성 높은 메시지 구독과 처리가 가능하다. 이러한 구조는 Kafka가 로그 수집, 이벤트 스트리밍, 데이터 파이프라인 등 다양한 실시간 데이터 처리 시스템에서 핵심 인프라로 사용되는 중요한 이유 중 하나이다.
3. 컨슈머 그룹

Kafka 브로커는 높은 처리 성능을 위해 하나의 토픽을 여러 개의 파티션으로 분할하여 병렬로 처리한다. 각 파티션은 독립적으로 읽을 수 있기 때문에, 이를 적절히 분산 처리하면 전체 메시지 처리량을 크게 향상시킬 수 있다. 그러나 여러 개의 파티션을 단 하나의 컨슈머가 모두 처리하도록 구성할 경우, 컨슈머의 처리 속도가 병목이 되어 성능 저하가 발생할 수 있다.
이러한 문제를 해결하기 위해 Kafka는 컨슈머 그룹(Consumer Group) 이라는 개념을 제공한다. 컨슈머 그룹은 하나 이상의 컨슈머가 논리적으로 하나의 그룹을 이루어 동일한 토픽을 구독하는 구조이다. 컨슈머 그룹을 사용하면 토픽의 여러 파티션을 그룹 내 컨슈머들 간에 분산하여 병렬로 처리할 수 있으며, 이를 통해 처리 성능과 확장성을 동시에 확보할 수 있다.
컨슈머 그룹에 속한 각 컨슈머는 토픽 파티션의 소유권(ownership) 을 나누어 가진다. 예를 들어, 파티션이 3개로 구성된 토픽 A를 2개의 컨슈머가 하나의 컨슈머 그룹으로 구독하는 경우를 생각해 볼 수 있다. 이때 컨슈머 0은 파티션 0의 소유권을 가지고 해당 파티션의 메시지를 소비한다. 반면 컨슈머 1은 파티션 1과 2의 소유권을 가지며, 이 두 파티션의 메시지를 소비한다. 이처럼 동일한 컨슈머 그룹에 속한 컨슈머들은 자신에게 할당된 파티션에 대해서만 메시지를 읽는다.
그렇다면 컨슈머 그룹에 새로운 컨슈머가 추가되거나, 기존 컨슈머가 장애나 종료로 인해 그룹을 이탈하게 되면 어떻게 될까? 이 경우 컨슈머 그룹 내부에서는 파티션 소유권을 다시 분배하는 과정이 발생한다. 이러한 파티션 소유권 재조정을 리밸런싱(Rebalancing) 이라고 한다.
리밸런싱은 컨슈머 그룹 내 일부 컨슈머의 상태가 변경되더라도, 전체 그룹이 지속적으로 토픽을 안정적으로 구독할 수 있도록 보장하는 메커니즘이다. 이를 통해 컨슈머의 증감이나 장애 상황에서도 메시지 소비가 중단되지 않고 유연하게 이어질 수 있다. 다만 리밸런싱 과정은 내부 동작 방식과 설정에 따라 성능에 영향을 줄 수 있는 요소이므로, 이에 대한 자세한 내용은 별도의 글에서 다루는 것이 적절하다.
참고자료
https://devboi.tistory.com/659
https://zzzzseong.tistory.com/107
https://curiousjinan.tistory.com/entry/understand-kafka-partitions
https://dkswnkk.tistory.com/736
'카프카' 카테고리의 다른 글
| [Kafka] 당신의 카프카는 zero copy입니까? (0) | 2026.03.29 |
|---|---|
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정 요약 (0) | 2026.03.22 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완)) (0) | 2026.03.21 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2) (0) | 2026.03.21 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(1) (0) | 2026.03.21 |