‼️💡 최종 개선 결과 💡‼️
- 초당 처리량 362.12건 → 6,767.27건
- 약 18.7배 성능 향상
총 3편의 내용으로 구성된 개선 과정이다.
2편 :
2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2)
[Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2)
‼️💡 최종 개선 결과 💡‼️- 초당 처리량 362.12건 → 6,767.27건- 약 18.7배 성능 향상총 3편의 내용이다.3차 구현조회는 단일 서버, 처리는 Kafka Consumer 분산 처리 2차 구현에서는 target 단위 Redis
to-travel-coding.tistory.com
3편(완) :
2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완))
[Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완))
‼️💡 최종 개선 결과 💡‼️- 초당 처리량 362.12건 → 6,767.27건- 약 18.7배 성능 향상총 3편의 내용으로 구성된 개선 과정이다.더보기2026.03.21 - [카프카] - [Kafka] Parallel-Consumer을 통한 알림 성능
to-travel-coding.tistory.com
개요
프로젝트를 진행하는 과정에서 알림 기능을 추가해야 했다.
기능 요구조건은 아래와 같았다.
- 사용자 1명당 N개의 알림을 받을 수 있다.
- 추후 알림 별 시간 설정 기능이 추가될 수 있으나, 현재 모든 알림이 동일한 시간에 제공된다.
- 사용자는 알림 수신 여부를 설정할 수 있다.
알림 수신 여부 설정
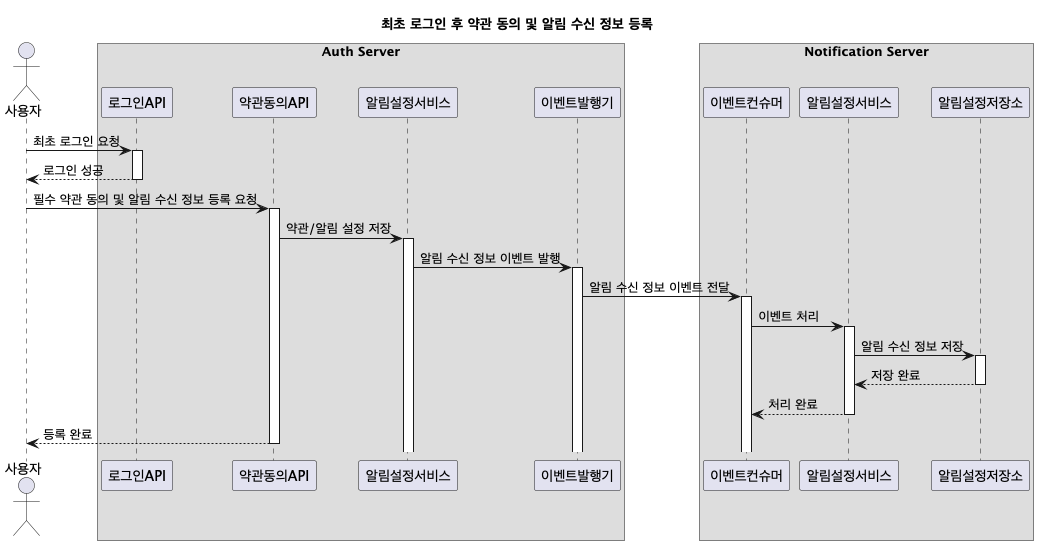
- 사용자가 최초 로그인을 할 때 필수 약관 동의 및 알림 수신 정보 등록을 요청한다.
- 알림 수신 정보 이벤트를 발행한다.
- Notification 서버는 이를 받아 알림 수신 정보를 저장한다.
1차 구현
@Transactional
@Scheduled(cron = "0 30 8 * * *", zone = "Asia/Seoul")
public void run() {
Instant now = Instant.now();
targetRepository.findByResolvedFalseAndEnabledTrueAndNextSendAtLessThanEqual(now).forEach(target -> {
boolean success = dispatchService.sendNotification(target.getUserId(), target.getTicketId(), target.getNextSequence());
if (success) {
target.advanceAfterSuccess();
targetRepository.save(target);
}
});
}구현은 위와 같았다.
- 데이터베이스에서 알림 대상이 되는 타겟을 먼저 찾는다.
- 각 타겟을 직접 sendNotification 메서드를 통해 전송한다.
- 현재 실제 SSE 발송은 없고, db 저장만 진행한다.
- 타겟의 알림 정보를 갱신한다.
이와 같이 구현했더니 아래와 같은 문제가 발생했다.
- 한 트랜잭션 내부에 너무 많은 작업이 묶인다.
- 배치 청크 처리 작업이 없어 db 부하가 커질 수 있다.
- 실패 처리가 존재하지 않는다.
- 서버가 여러 대 구동되어 스케쥴러가 동시 작동한다면 중복처리 문제가 발생할 수 있다.
문제 해결
알림 중복 해결
여러 서버에서 동일한 스케줄러가 동시에 실행될 경우, 같은 알림 대상이 중복 처리될 수 있다는 문제가 있었다.
특히 기존 구현은 단순 조회 후 바로 처리하는 방식이었기 때문에, 서버 A와 서버 B가 같은 시점에 동일한 target을 조회하면 둘 다 같은 알림을 저장하거나 발송할 수 있었다.
이를 방지하기 위해 서버 단위 Redis 기반 분산 락을 적용했다.

// 예시 코드
public void run_db_only_with_redis_lock() {
String token = distributedLockService.tryLock("scheduler:run-db-only", Duration.ofMinutes(5));
if (token == null) {
return;
}
try {
run_db_only();
} finally {
distributedLockService.unlock("scheduler:run-db-only", token);
}
}처리 방식은 다음과 같다.
- 스케줄러 실행 전 Redis에 특정 lock key를 기준으로 락 획득을 시도한다.
- 락 획득에 성공한 서버만 실제 알림 처리 로직을 수행한다.
- 락 획득에 실패한 서버는 해당 스케줄 실행을 즉시 종료한다.
- 작업이 끝나면 락을 해제한다.
- 락 해제 시에는 token 기반 검증을 사용하여, 자신이 획득한 락만 해제할 수 있도록 한다.
이 방식으로 여러 서버가 동시에 스케줄러를 실행하더라도 실제 알림 처리 로직은 한 서버에서만 수행되도록 보장할 수 있다.
적용한 락 방식은 다음과 같다.
- Redis
SETNX기반 락 획득 - TTL을 포함한 락 만료 시간 설정
- Lua Script를 이용한 안전한 unlock 처리
다만 이 방식은 스케줄러 전체를 한 번에 잠그는 방식이기 때문에, 향후 처리량이 더 커질 경우에는 target 단위 처리나 큐 기반 분산 처리 구조로 확장하는 것이 더 적합할 수 있다.
2차 구현
1차 구현에서는 스케줄러 전체에 대해 하나의 분산 락을 거는 방식으로 중복 실행을 막았다.
이 방식은 구현이 단순하고 빠르게 적용할 수 있다는 장점이 있었지만, 스케줄러 전체가 하나의 락에 묶이기 때문에 병렬 처리에 제약이 있었다.
이를 개선하기 위해 2차 구현에서는 타겟별 분산 락을 적용했다.
처리 흐름은 다음과 같다.
- 스케줄러가 due target 목록을 조회한다.
- 각 target에 대해
ticketId기준으로 개별 분산 락 획득을 시도한다. - 락 획득에 성공한 target만 실제 처리한다.
- 처리 성공 시 알림 정보와 target 상태를 갱신한다.
- 처리 종료 후 해당 target의 락을 해제한다.
- 락 획득에 실패한 target은 이미 다른 서버가 처리 중인 것으로 보고 건너뛴다.
이 방식의 장점은 다음과 같다.
- 스케줄러 전체를 하나의 락으로 막지 않아도 된다.
- 여러 서버가 동시에 실행되더라도 서로 다른 target은 병렬 처리할 수 있다.
- 동일한 target만 중복 처리되지 않도록 제어할 수 있다.
다만 주의할 점도 있다.
- 락 key 설계를 명확히 해야 한다.
- 락 TTL이 너무 짧으면 처리 중 락이 풀릴 수 있다.
- 처리 시간이 긴 경우 TTL 연장 전략이 필요할 수 있다.
예를 들어 락 key는 다음과 같이 구성하였다.
LOCK:GREENROOM:TARGET:{ticketId}
이렇게 하면 같은 ticketId에 대해서만 상호 배타 처리가 가능하다.

// 예시 코드
@Transactional
public void run_with_target_lock() {
Instant now = Instant.now();
targetRepository.findByResolvedFalseAndEnabledTrueAndNextSendAtLessThanEqual(now).forEach(target -> {
String lockName = "TARGET:" + target.getTicketId();
String token = distributedLockService.tryLock(lockName, Duration.ofMinutes(5));
if (token == null) {
return;
}
try {
boolean success = dispatchService.sendNotification(
target.getUserId(),
target.getTicketId(),
target.getNextSequence()
);
if (success) {
target.advanceAfterSuccess();
targetRepository.save(target);
}
} finally {
distributedLockService.unlock(lockName, token);
}
});
}2차 구현의 한계
타겟별 분산 락 방식은 동일한 target에 대한 중복 처리를 방지하는 데에는 효과적이었다.
즉 여러 서버가 동시에 스케줄러를 실행하더라도, 같은 ticketId에 대해서는 하나의 서버만 실제 처리하도록 만들 수 있다.
하지만 이 방식에도 여전히 중요한 한계가 존재했다.
가장 큰 문제는 모든 서버가 스케줄러 시작 시점에 동일한 데이터베이스 조회를 수행한다는 점이다.
처리 흐름을 보면:
- 서버 A, B, C가 같은 시각에 스케줄러를 시작한다.
- 각 서버는 모두 due target 조회 쿼리를 실행한다.
- 조회된 target에 대해 각자 Redis 락 획득을 시도한다.
- 락을 획득한 서버만 처리하고, 나머지는 해당 target을 건너뛴다.
즉, 실제 처리 중복은 줄어들었지만, 조회 부하는 그대로 중복 발생한다.
이 방식에서 발생할 수 있는 문제는 다음과 같다.
- 모든 서버가 동일한 due target 목록을 동시에 조회하므로 DB read 부하가 커진다.
- target 수가 많아질수록 각 서버가 불필요하게 대량 데이터를 읽게 된다.
- 결국 처리 자체는 한 번만 일어나더라도, 조회 비용은 서버 수만큼 반복된다.
- 예를 들어 서버가 5대이고 due target이 10만 건이라면, 최악의 경우 동일한 10만 건 조회가 5번 발생할 수 있다.
- 이는 ticketId 기반 Redis 락으로는 해결되지 않는 문제이며, DB에 불필요한 부하를 유발한다.
또한 추가적인 비효율도 존재한다.
- 조회 후 대부분의 target에서 락 획득에 실패할 수 있으므로, 읽어온 데이터의 상당수가 실제 처리되지 않고 버려질 수 있다.
- Redis 락 획득 시도 자체도 target 수만큼 발생하므로, Redis 부하 역시 커질 수 있다.
- 즉 중복 처리 방지는 가능하지만, 전체 시스템 관점에서는 조회 비용과 락 경쟁 비용이 여전히 크다.
정리하면, 2차 구현은 다음과 같은 특징을 가진다.
- 장점:
- 동일 target 중복 처리 방지
- 서로 다른 target은 병렬 처리 가능
- 한계:
- 모든 서버가 동일한 due target을 동시에 조회
- DB 조회 부하가 서버 수만큼 증가 가능
- 락 획득 실패 대상에 대해서도 조회 비용이 이미 발생
- 대규모 트래픽 환경에서는 비효율이 커질 수 있음
따라서 이 방식은 중복 처리 방지에는 유효하지만, 조회 비용 최적화까지 해결한 구조는 아니다.
이 문제를 근본적으로 해결하려면 다음과 같은 구조가 필요하다.
- 스케줄러 자체를 단일 실행으로 제한하는 전역 분산 락 방식
- 또는 스케줄러는 enqueue만 수행하고 실제 처리는 메시지 큐 consumer가 담당하는 구조
즉 2차 구현은 1차 구현보다 처리 단위는 세밀해졌지만,
모든 서버가 동시에 DB를 조회한다는 구조적 한계는 여전히 남아 있다.
'카프카' 카테고리의 다른 글
| [Kafka] 당신의 카프카는 zero copy입니까? (0) | 2026.03.29 |
|---|---|
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정 요약 (0) | 2026.03.22 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(3(완)) (0) | 2026.03.21 |
| [Kafka] Parallel-Consumer을 통한 알림 성능 개선 과정(2) (0) | 2026.03.21 |
| [Kafka] Group, Topic, Record, Consumer, Partition 총 정리 (0) | 2026.01.05 |